Given that database transactions have been around for decades, I was surprised to find that some concepts and implementations still don’t have generally agreed-upon terminology, especially across vendors. And even the ANSI SQL standard’s description of Isolation Levels has been found to be lacking in places.
I made some notes recently about selected topics in database transactions for my own reference as I was reading through these parts. Beware that my simplifications may have subtle errors too! I have added a few good references at the end.
Isolation Levels
When transactions execute concurrently, they can interfere with each other when one or more of them do write operations. Due to this, transactions might observe different data in the database compared to when they run sequentially. The end state of the database might also turn out to be different compared to when they run sequentially.
Figure 1 is something I came up with, to depict this. A database is changing its state over time as one transaction executes. The circles represent states and arrows represent transitions between them. Dotted arrows show which “isolation level” (shown in quotes) can access which of these states.
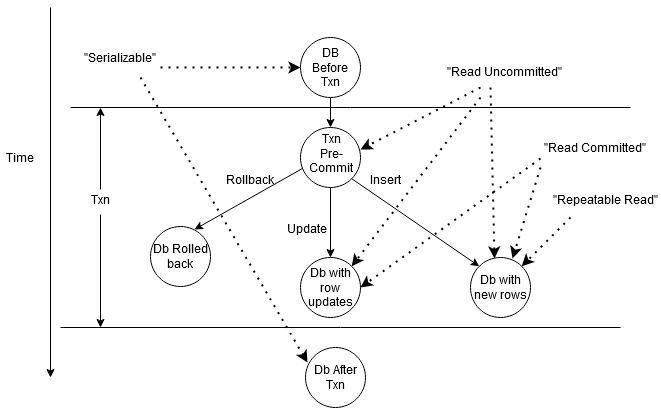
The ANSI SQL standard also defines names for certain types of interference, and uses these names to define the Isolation Levels instead:
- T1 writes -> T2 reads -> T1 rolls back => DIRTY READ. i.e. T2 read data that got rolled back!
- T1 reads -> T2 commits -> T1 reads different values => NON REPEATABLE READ
- T1 reads rows based on a predicate -> T2 commits -> T1 reads new rows for that predicate => PHANTOM READ (a variation of 2 above)
Isolation Levels defined according to the interference phenomena defined above:
| Isolation Level | Phantom Read | Non Repeatable Read | Dirty Read |
| Serializable | ❌ | ❌ | ❌ |
| Repeatable Read | ✔ | ❌ | ❌ |
| Read Committed | ✔ | ✔ | ❌ |
| Read Uncommitted | ✔ | ✔ | ✔ |
Note: Serializable actually refers to transactions being scheduled such that an equivalent serial schedule exists. The above three phenomena being disallowed are a necessary but not sufficient condition for serializability!
While the intent of the standard was to decouple it from implementation details, historically, both the interference types and the levels were defined in the context of implementation using a “lock based” transaction scheduling mechanism. This consists of making transactions request for a lock before reading/writing rows.
Two Phase Locking
- A simple way to achieve a Serializable schedule is to ensure that there is only one unlock phase for each transaction, which is at the end (proof not included here). This is called Two Phase Locking.
- Note that Two Phase Locking does not prevent deadlocks! Because the transactions may request the same two resources in opposite orders.
Reordering database operations
- Given the following schedule across two transactions 1 and 2:
R1(X), W2(Y), R2(X), W1(Y)
it’s obvious that you can reorder them as follows without losing correctness:
W2(Y), R1(X), W1(Y), R2(X)
In general, any two successive operations can be swapped as long as they are:- from different transactions
- AND (they access different variables, OR neither of them is a write)
- A series of such reorderings can be used to check if a Serializable schedule can be obtained from a given schedule.
Snapshot Isolation
- Some databases let you have multiple temporary copies of the same data item, each with its own version number and timestamp.
- Each transaction can work on its own copy of the data item. When the time to commit comes, the transaction is allowed to go ahead and commit only if no other transaction has committed to any of the same data items from the time this transaction started. This is called Snapshot Isolation.
- Each transaction reads the copy of its data as it was when the transaction started. Concurrent writes by other transactions are handled using multi-version storage for values. But still, a “write skew” anomaly, described below, is possible.
Write Skew
- Write skew can happen in Snapshot Isolation. In the below schedule A and B get swapped, although both transactions sought to make them equal to each other.
| Time | Txn 1 | Txn 2 |
| T1 | R(A) | |
| T2 | R(B) | |
| T3 | W(B=A) + Commit | |
| T4 | W(A=B) + Commit |
References
- A History of Transaction Histories – a blog post by Arjun Narayan (formerly at Cockroach Labs). In particular, he links to a paper by Atul Adya that treats concurrent behaviour exhaustively.
- An Introduction to Transaction Isolation Levels – by Prof. Daniel Abadi
- The CMU Database Systems course has lectures on Concurrency Control Theory and 2-3 follow ups which cover transactions, lock manager, two phase locking, multi-version concurrency control
- Martin Kleppmann’s “Designing Data Intensive Applications” too covers transactions: Transactions