The AWS Firecracker paper is fascinating because Amazon has implemented a new Virtual Machine Monitor (VMM) which closely matches the requirements of their AWS Lambda service. While doing so, they carefully navigated the space of existing virtualization options, reused the best parts where they could, and implemented the rest. They also describe how they successfully rolled this out in production. I thought this paper provides a great example of the big technical possibilities open to large Cloud providers. This post is my simplified notes from that paper. There’s also a Resources section at the end of this post with links to talks and other material about Firecracker.
What is Firecracker?
Firecracker is a new Virtual Machine Monitor (VMM) specialized for Serverless (AWS Lambda) workloads, but generally useful for containers, functions and other compute workloads within a reasonable set of constraints. Firecracker’s design has been heavily influenced by the need to run Serverless workloads.
What kind of a VMM does AWS Lambda need?
Due to the rise of Serverless and Containerized apps, there is a need for different kind of features from a VMM:
- Containerized apps are more lightweight than traditional VMs. So a single hardware instance should be utilized to host apps of multiple customers, in order to make better use of the hardware.
- Serverless apps often run for a very short interval, hence again the need for the ability to reuse the same hardware across different customers.
In order to spawn more – and short lived – Containers/Serverless runtimes on the same hardware, the VMM should be able to launch each of them quickly, with minimal overhead, and also ensure great isolation between them.
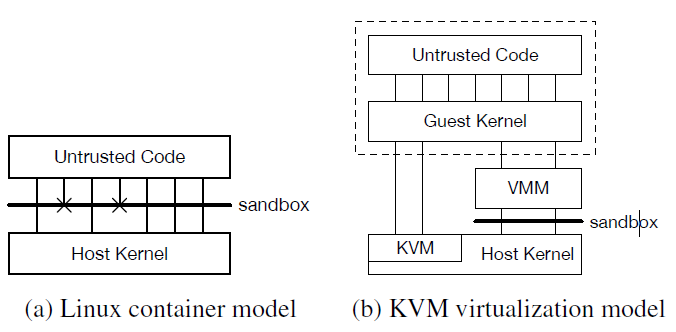
Limitations of existing options
Figure 1 above shows two common ways virtualization is implemented. One option is using a container runtime (say Docker). Docker uses the host OS’s kernel for all its containers, which leads to a lesser degree of isolation. Hence the only way to make it more secure is by restricting certain syscalls, which would then break apps which need those syscalls!
The other option is to use Linux’s KVM feature. KVM transforms the kernel itself into operating like a VMM. QEMU is a VMM that uses KVM. If the KVM feature is not enabled, QEMU literally emulates the hardware by translating machine code from the guest OS to the host OS, on-the-fly. QEMU, however, is large (1.4 million lines of code) and featureful. Thus not suited for the low overhead scenario of a Serverless runtime.
The design of Firecracker
So Firecracker was created as a new VMM to overcome these limitations of existing VMMs for Serverless/Container workloads. Note that Firecracker uses KVM underneath just like QEMU. And instead of writing a VMM from scratch, they picked up Google Chrome OS’s existing crosvm codebase and simplified it to meet their needs! Firecracker is about 81,000 lines of Rust code.
They removed many device drivers and retained only a handful of device types. They do not allow guest OSes to use the underlying filesystem’s API, in order to reduce the security attack surface [not entirely clear to me]. Firecracker also has the following limitations, since none of these are needed for the main use case of Serverless applications:
- Firecracker does not offer a BIOS
- It cannot boot arbitrary kernels
- Does not emulate legacy devices
- Does not support VM migration
Firecracker reuses the following aspects of the Linux kernel via KVM: process management, memory management, block I/O and the TUN/TAP network interface. This helps them build on top of well proven components, and also reduces operational burden because the standard Linux tools continue to work (ps, top, kill etc). Firecracker provides a RESTful management API.
Firecracker lets you set thresholds for the amount of CPU, memory, IO and network available to a guest. But this is not as sophisticated as Linux’s cgroups. Firecracker enables many of the security features of the Linux kernel to prevent side-channel attacks. This can lead to a slight dip in performance.
Section 4 of the paper describes how Firecracker integrates with AWS Lambda’s control plane, and the production roll out. The production roll out part and the issues they encountered are worth reading, and are a good example of the commitment to engineering necessary to pull this off.
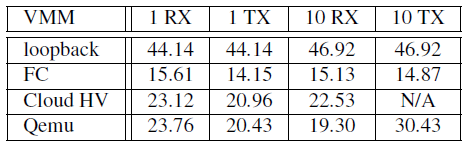
Performance Evaluation
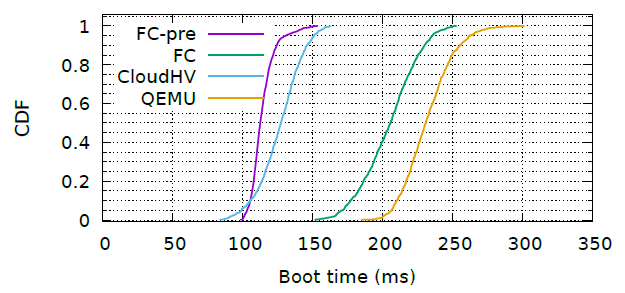
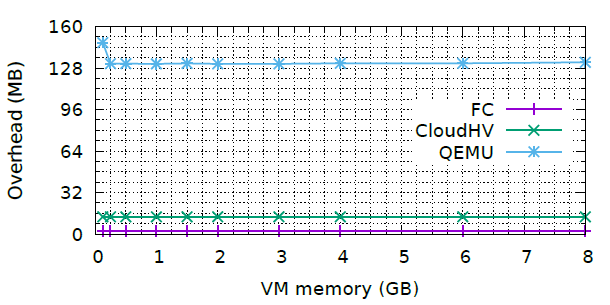
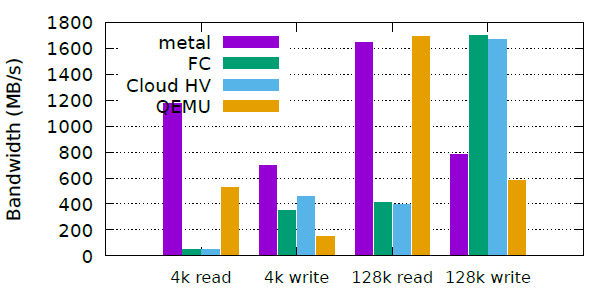
A few graphs from the paper.
Resources
- Paper presentation at NSDI 2020 – link
- Firecracker FAQ (very good)
- Firecracker on Github
- Another nice Youtube talk – link