TiDB is an interesting new database, and PingCAP is the company driving most of its development. Recently I read the paper written about it, titled TiDB: A Raft based HTAP database, partly due to my interest in its Rust-based TiKV component. I found the paper to be comprehensive and well written. Below is my bullet points style summary of it.
Overview
- Ti = Titanium. HTAP = Hybrid Transactional and Analytical Processing
- A unified system that supports both Transactional Processing (TP) and Analytical Processing (AP) workloads, albeit with separate storage layers (TiKV, TiFlash). Having a single system simplifies development and ops.
- High level architecture of TiDB (PD = Placement Driver)
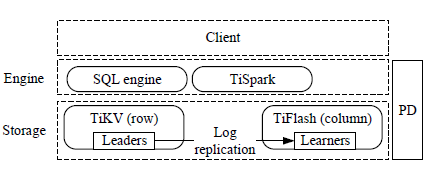
- For TP, there are multiple Raft groups that write into RocksDB. This ensures High Availability.
- Each Raft group handles one range partition of a table’s key space (called Region).
- For AP, the above Raft groups have a learner node (innovation) which helps replicate data into a column store, asynchronously and quickly.
- Challenges in HTAP: i) providing fresh data on AP, and ii) preventing AP and TP workloads from interfering with each other. The design addresses these specific challenges, and the performance evaluation section measures the results.
- The SQL engine may use both the stores in tandem to satisfy queries!
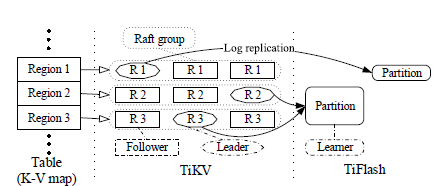
- A more detailed architecture diagram:
Transaction Processing
- TiKV
- This is the TP storage layer. Consists of multiple Raft groups, each handling one range partition of the key space (called Region). Data store is RocksDB. Row key for RocksDB is concat(table id, row id).
- Supports 2 Phase Commit, implemented based on Google’s Percolator model of incremental processing. Explained in more detail here.
- Optimizations:
- Between Raft leader and followers
- Concurrency and parallelism are added as described below
- Leader continues to accept new client requests and committing to log before applying previous requests
- Leader sends client reqs to followers parallelly when it’s committing them, and also batches them up (not sending one req per message)
- If error when applying requests on leader or getting quorum, then client is informed and the log is replayed as necessary.
- Leader continues to accept new client requests and committing to log before applying previous requests
- Concurrency and parallelism are added as described below
- Between Raft leader and clients
- Optimize reads by avoiding the canonical dummy write + quorum consensus using 3 techniques hinted at in the Raft paper (Section 8): Lease index, Lease Read and Follower Read.
- Optimize reads by avoiding the canonical dummy write + quorum consensus using 3 techniques hinted at in the Raft paper (Section 8): Lease index, Lease Read and Follower Read.
- Decongest servers with too many hot Regions and spread the load
- Based on observed workloads, PD can merge small Regions (to reduce metadata traffic overhead) or split large Regions that have heavy traffic.
- Between Raft leader and followers
- This is the TP storage layer. Consists of multiple Raft groups, each handling one range partition of the key space (called Region). Data store is RocksDB. Row key for RocksDB is concat(table id, row id).
- PD (Placement Driver): Stores and updates Region metadata. It is also the timestamp oracle (timestamps are used as txnids). PD has no separate persistent state.
Analytical Processing
- TiFlash
- The AP storage layer. A column store. Consists of a Raft learner to obtain the logs from the TP side. Only non-rollbacked row change entries are selected, buffered up to reach a certain size/time interval and then converted into columnar format and persisted.
- Translation to column format needs schema awareness, so a schema sync module in the Raft learner fetches schema from TiKV either periodically or on demand.
- They’ve created DeltaTree, a new approach to syncing records from the Raft logs to column format. This ensures that logs can be processed at a high throughput.
- The AP storage layer. A column store. Consists of a Raft learner to obtain the logs from the TP side. Only non-rollbacked row change entries are selected, buffered up to reach a certain size/time interval and then converted into columnar format and persisted.
Hybrid Transaction and Analytical Processing
- SQL engine is based on the (Google) Percolator model for incremental processing. There is both a rule based and a cost based optimizer.
- TP
- Txns are a joint work of TiKV, SQL Engine and Placement Driver
- ACID with Snapshot Isolation,Repeatable Read and Read Committed modes
- Optimistic and Pessimistic Txns
- AP
- A rich rule based optimizer, and a cost-based optimizer. Co-processor which executes some aspects of the query within the storage layer without involving the SQL engine
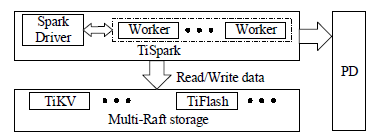
- TiSpark – supports Spark APIs on top of TiDB. Arch diagram below:
- Isolating TP and AP
- TiKV and TiFlash are kept on different physical servers
- But a given query might use either, depending on what kind of access the query needs (row scan or index scan => TiKV, column scan => TiFlash)
The paper also has a fairly detailed performance evaluation section, which I have not summarized above. I encourage you to take a look at the paper itself for that.